En estos días de Navidad, uno de nuestros chicos (@dormidera) esta publicando en su blog 1024Megas una serie de artículos sobre las alternativas a la red TOR, te recomendamos que visites su blog para ver esta serie de artículos.

martes, 27 de diciembre de 2016
lunes, 26 de diciembre de 2016
Controlando twitter desde la terminal con python

Autor: @PanaPunk
Todos conocemos twitter, algunos incluso lo usamos para difundir las entradas de nuestro blog u otras noticias de interés, también nos sirve para estar a la última en nuevas tecnologías, avances científicos o ser los primeros en ver el nuevo vídeo de el Rubius...
La publicación de cada tweet es instantánea y accesible desde cualquier lugar del ciber-universo conocido, y es que twitter, por su naturaleza y sencillez, puede llegar a ser mucho más que una simple aplicación de microbloging, ya que, no sé si lo has pensado alguna vez, pero ¿y si la usáramos para obtener notificaciones de otras aplicaciones, por ejemplo?, ¿o quizá para controlar máquinas de manera remota…?
sábado, 24 de diciembre de 2016
Ojo con los Robots

El archivo robots.txt es un fichero con una lista de robots no admitidos,
la cual te permite restringir el acceso a tu sitio selectivamente. Si hay
páginas que no quieras que se indexen por los buscadores, puedes configurarlo
aquí, y si hay un buscador al que quieres denegar el acceso, también.
Los buscadores quieren indexar toda la información posible,
y así cuando llegan hasta nuestro sitio web lo rastrean todo. El problema surge
cuando quieres evitar que ciertas páginas se incluyan en sus índices, ¿qué
hacemos entonces?
miércoles, 21 de diciembre de 2016
Agregar exploits/módulos a Metasploit
Autor: @txambe
El articulo de hoy hablaremos de incluir dentro de Metasploit, exploit que no estén en su base de datos , este proceso lo podremos realizar o desde línea de comandos o por entorno gráfico.
El articulo de hoy hablaremos de incluir dentro de Metasploit, exploit que no estén en su base de datos , este proceso lo podremos realizar o desde línea de comandos o por entorno gráfico.
domingo, 18 de diciembre de 2016
¿Configuras de forma correcta tus redes sociales? Twitter (Parte 2).

Autor: @dsu4r3z
Hola amigos, ¿cómo ha ido la semana? Esperamos que
productiva y con muchas ganas de seguir aprendiendo.
Vuelvo a las andadas por aquí para mi segunda parte sobre
configuración, securización y privacidad en redes sociales. Ahora le toca el
turno a Twitter. Esos 140 caracteres mágicos que tanto poder tienen tanto para
bien como para mal (si no tienes cuidado, obviamente).
Y para ello hay que tener mucho cuidado con lo que se
publica, por supuesto. Esto también forma parte de nuestra seguridad y de
nuestra propia persona.
¡Vamos a comprobar cómo hacemos nuestra cuenta de Twitter
segura! ¿Me seguís? Pues adelante.
Lo primero que tenemos que hacer es irnos a la parte derecha
de nuestro perfil y pinchar en el avatar de nuestra fotografía. Ahí tendremos
la opción de Configuración.
viernes, 16 de diciembre de 2016
Ataques Bluetooth

DISCLAIMER: Honeysec
no se hace responsable de cualquier uso que se le pueda dar a las herramientas
que aparecen en el siguiente articulo, incluidos ataques a cualquier dispositivo
móvil o tablet. Estas herramientas han sido publicadas con propósitos
educativos y sin ninguna garantía.
Bluetooth es un sistema inalámbrico de corto alcance utilizado
en redes de área personal (PAN) o una red de dispositivos cerca de una sola
persona. Los dispositivos Bluetooth incluyen teléfonos inteligentes, asistentes
digitales personales (PDA) y dispositivos informáticos.
La gama de Bluetooth fue diseñada originalmente para cerca de tres metros pero su alcanze es a menudo más lejos, y se extiende más allá del espacio personal de una persona. Los atacantes han encontrado que los ataques a estas redes son posibles. Dos ataques comunes son bluesnarfing y bluejacking. Ambos ataques son mucho más fáciles cuando los dispositivos Bluetooth permanecen en modo Discovery.
martes, 13 de diciembre de 2016
Dame tu email y te diré …

Autor: @RaulRenales
Es conocido desde hace tiempo que es posible el trackeo de emails de tal manera que podamos obtener información de que ocurre con cada uno de los emails que mandamos, el concepto de tracking en emails está muy ligado al marketing, donde prácticamente no hay sistema de envíos masivos que no incluya un “pixel” que obtiene información jugosa sobre los receptores de los emails.
Dentro de los correos tradicionales que casi todo el mundo usa (Gmail por ejemplo) es posible añadir herramientas que nos permiten realizar ese mismo trackeo comercial pero para el seguimiento de nuestros correos personales.
domingo, 11 de diciembre de 2016
¿Configuras de forma correcta tus redes sociales? Facebook (Parte 1)

Autor: @dsu4r3z
Ahhhh, las redes sociales… Ese
espacio en el que compartimos todas nuestras vivencias, fiestas con los
colegas, mostramos nuestro ego… Lo que está claro es que sin ellas en la
actualidad, no podemos vivir sin ellas, pero… ¿Sabemos lo que compartimos y con
QUIÉN lo compartimos? ¿Sabemos toda la información que estamos dando a quién
sabe qué personas?
He encontrado de vez en cuando a
gente preguntándome por determinados problemas con terceras personas o amigos
por temas tan variopintos relacionados con la seguridad o la privacidad de su
cuenta. ¿Cómo cambiar todos estos problemas? Pues la solución no es difícil.
Simplemente hay que ‘toquetear’ y mirar un poco la aplicación ;)
sábado, 10 de diciembre de 2016
Máquinas virtuales Linux “deshechables” desde el navegador web y en unos segundos.

created by: @panapunk
No son pocas las veces que me he visto en la tesitura de tener
que virtualizar una máquina Linux para poder hacer un par de operaciones que mi
Sistema operativo no me permite o no debo hacer desde la máquina anfitrión, o
simplemente otras muchas situaciones que nos requieren virtualizar un Ubuntu, Debian, Fedora, CentOS o Arch Linux
lo antes posible, una máquina de usar y tirar.
Pero claro, es una tarea que requiere un tiempo mínimo de
instalación o arranque de life CD, o incluso tener que descargar la ISO para
hacerlo. Y en muchas de esas ocasiones tras el arranque, hago las dos o tres
tareas que necesito y me olvido de la máquina.
jueves, 8 de diciembre de 2016
Paseando por Cybercamp 2016

Autor: @Dormidera
El pasado jueves 2 de diciembre se inauguró la tercera edición de Cybercamp. Un evento creado por el Instituto Nacional de Ciberseguridad (INCIBE), lleno de una gran variedad de actividades dentro del mundo de la "CiberSeguridad".
Charlas y talleres impartidos por los mejores profesionales a nivel nacional, una carpa entera dedicada a las familias con decenas de actividades y talleres. Grandes competiciones, El hackaton, campeonato de desarrollo seguro y los retos CtF tanto en su versión en grupo como individual y las zonas de Ciberempleo y los NetworkingGames, en los que participaban varios miembros de la asociación.
lunes, 5 de diciembre de 2016
SVG Scripting How to

Autor: @RaulRenales
El pasado sábado publique en el blog de Honey un artículo
sobre la pérdida de privacidad originada por una vulnerabilidad
en mozilla, en un objeto que gestiona animaciones SVG.
A raíz del artículo hay mucha gente que me ha preguntado
sobre las imágenes vectoriales del formato SVG y las implicaciones en seguridad
que este tipo de formatos puede acarrear.
Primero de todo
repasemos que es una imagen SVG:
Gráficos Vectoriales Redimensionables o SVG es un formato de
gráficos
vectoriales bidimensionales, tanto estáticos como animados, en
formato XML, cuya especificación
es un estándar abierto desarrollado por el W3C
desde el año 1999.
sábado, 3 de diciembre de 2016
Usuarios TorBrowser al descubierto (SVG Scripting)

Autor: @RaulRenales
Es conocido que uno de los problemas de nuestra era es la perdida de privacidad que estamos sufriendo a medida que incorporamos las nuevas tecnologías en nuestro día a día. En este sentido mucha gente busca soluciones para no ofrecer sus datos o simplemente para poder obtener una dirección ip distinta por donde navegar de una manera mas anónima, allá cada uno con sus objetivos.
domingo, 27 de noviembre de 2016
Fundamentales. Directorios II

Para terminar con el tema de los directorios y después de ver en el post anterior los comandos relativos a ellos, vamos a ver algunos directorios que debemos de conocer en Linux y que contienen. Hay que tener en cuenta que cada distribución de Linux puede tener otros directorios o tener una ubicación distinta. Los que vamos a ver son, hasta donde yo conozco, comunes a muchos sistemas *nix (SCO-UNIX, HP-UX, Linux…etc.).
/home: Es el directorio donde se van a crear los subdirectorios de cada usuario del sistema a excepción del usuario root. Por ejemplo, cuando creemos un usuario llamado pepe se creará, al menos, un subdirectorio con ese nombre en /home.
lunes, 21 de noviembre de 2016
Wordpress, Temas y Botnets
By @elchicodepython (Samuel López)
Cada vez más escucho a más personas decir barbaridades del estilo ¡cómo me voy a
infectar con un tema si es solo la parte gráfica!
No me preocuparía tanto de no ser porque es en el propio sector del desarrollo web
donde lo estoy escuchando actualmente.
Esto tiene una explicación y es debido a que como la tendencia en pequeños
mercados a abaratar costes muchas veces llega a un punto de desarrollo
insostenible.
sábado, 19 de noviembre de 2016
Fundamentales. Directorios

Autor: @jantoniorobledo
Hoy
vamos a ver dos cosas: como movernos en el árbol de directorios y otros comandos
útiles para manipularlos
Que es un directorio
Pues de forma básica es eso que conocemos en
Windows como carpeta (para mí siempre serán directorios a pesar de Microsoft J). En la Wikipedia podemos encontrar
esta definición de directorio:
“En informática,
un directorio es un contenedor virtual en el que se almacenan una agrupación de
archivos informáticos y otros subdirectorios, atendiendo a su contenido, a su
propósito o a cualquier criterio que decida el usuario. Técnicamente, el
directorio almacena información acerca de los archivos que contiene: como los
atributos de los archivos o dónde se encuentran físicamente en el dispositivo
de almacenamiento.”
lunes, 14 de noviembre de 2016
Presentada el aula movil de HoneySEC en #HoneyCon16 (Proyecto Recycling)

El pasado 12 de noviembre se presento el resultado del proyecto Recycling de HoneySEC. Un proyecto iniciado hacia el mes de febrero con un simple Tweet que pedía la entrega de portátiles que la gente no usase en sus casas o trabajos.
Rápidamente comenzaron a contestar personas anónimas de diferentes puntos del país, incluso de sudamerica solicitando información para donar sus equipos. En pocas semanas llegaron una docena de portátiles y de esta manera arrancamos el proceso de Recycling.
domingo, 13 de noviembre de 2016
Mini-Resumen: HoneyCon2016
El pasado viernes 11 de noviembre se inauguró el 2º Congreso de seguridad Ciudad de Guadalajara, Jornadas que prácticamente clausuran el año 2016 para la asociación HoneySec, un año en el que el denominador común fue la continua actividad de la misma, con 60 eventos dentro y fuera de nuestra ciudad.
Las jornadas se inauguraron por Raúl Renales como representante de HoneySec, Jesús de Andres como Director del centro asociado de la UNED en Guadalajara, Lucas Castillo como Diputado de la Excelentísima Diputación de Guadalajara y Jaime Carnicero como vice-alcalde de Guadalajara, en el acto se dio la bienvenida a ponentes y asistentes y se repasó la implicación de estas entidades en las jornadas.
domingo, 6 de noviembre de 2016
Fundamentals: HTTP – REFERER

Autor: @txambe
En el articulo de hoy vamos a revisar el tema de las
cabeceras de HTTP REFERER , para aquello que desconozcáis de que son , os pongo
el resumen que hay en la wikipedia.
Fuente: WiKipedia
HTTP referer (inicialmente un error ortográfico del término referrer)
es una cabecera HTTP
que identifica la dirección de la página web (es decir, la URI o IRI)
que creó el vínculo con el recurso que está siendo solicitado. A través del
chequeo del campo referer, la nueva página web puede determinar dónde se
originó la solicitud.
En la mayoría de los casos esto significa que cuando un
usuario hace clic a un hipervínculo
en un navegador web,
el navegador envía una solicitud al servidor que hospeda la página web destino
y dicha solicitud incluye el campo referer, que indica la última página que el
usuario visitó (aquella donde el usuario hizo clic al vínculo).
El registro del campo referer es utilizado con propósitos
estadísticos y promocionales por los sitios web y servidores web, pues les
permite identificar desde qué localización están siendo visitados.1
También es muy recomendable revisarse la RFC 2616,
sección 14.36 que explica en detalle el HTTP Referer y en
la sesión 15.1.3 se ven las
consideraciones de seguridad que deben cumplir los agentes de usuario
como por ejemplo no incluir el Referer cuando se pase de HTTPS a HTTP por los
problemas de exposición de información sensible.
En la siguiente imagen podemos ver un encabezado HTTP y como
el navegador web esta informando al servidor , a través de referer , que esta solicitando el recurso htaccess.html
se está realizando desde la portada de /http-headers-tool
se está realizando desde la portada de /http-headers-tool

No hay que confundirse con el metadato HTML Referrer
que se ocupa de especificar que valores va a contener el campo de
encabezado de petición Referer, según la política de
Referrer de la W3C que se aplique.
El Referer, al igual que el Etag han suscitado
bastantes sospechas respecto a su uso, utilizados por afectar la privacidad de
los usuarios. Mediante el Referer puede registrarse los hábitos de navegación
de las personas a través de la recolección de los saltos realizados entre
páginas, estableciéndose patrones de comportamiento en Internet.
Al realizar una
prueba de pentesting es importante revisar cual es el Referer entre peticiones
, para lo cual podemos aplicar la prueba
de seguridad OTG-AUTHN-001 para entender si las credenciales son
enviadas a través de un canal seguro.
domingo, 30 de octubre de 2016
Fundamentals: WAF ( Web Application Firewall )

Autor: @txambe
Hoy vamos a ver un tema muy interesante (por lo menos a mí
me lo parece) y son las distintas técnicas para realizar un fingerprint de los
firewall de aplicaciones web o más conocidos como WAF.
Bueno pues empecemos por el principio ¿Que es un firewall? es un sistema de seguridad que controla el
tráfico de una red, servidor o una aplicación, los puede haber tanto hardware
como software.
Se pueden diferenciar dos tipos de firewall :
·
Los firewalls de capa de red funciona a nivel de red (capa 3 del modelo OSI, capa 2 del
stack de protocolos TCP/IP) como filtro de paquetes IP. A este nivel se pueden
realizar filtros según los distintos campos de los paquetes IP: dirección IP
origen, dirección IP destino. En este tipo de firewall se permiten filtrados
según campos de nivel de transporte (capa 3 TCP/IP, capa 4 Modelo OSI), como el
puerto origen y destino, o a nivel de enlace de datos (no existe en TCP/IP,
capa 2 Modelo OSI) como la dirección MAC.
·
Los firewall de aplicaciones web, trabaja en el nivel de aplicación (capa 7 del modelo OSI),
de manera que los filtrados se pueden adaptar a características propias de los
protocolos de este nivel. Por ejemplo, si se trata de tráfico HTTP, se pueden
realizar filtrados según la URL a la que se está intentando acceder.
Un cortafuegos a nivel 7 de tráfico HTTP suele denominarse proxy, y permite que los pc de una organización entren a Internet de una forma controlada. Un proxy oculta de manera eficaz las verdaderas direcciones de red.
Los WAF funcionan en los siguientes modos::
·
Negative
Model (Blacklist based)
·
Positive
Model (Whitelist based)
·
Mixed/Hybrid
Model (Blacklist & whitelist model)
Las formas en que podemos implementar un WAF son:
·
Reverse
proxy
·
Inline
·
Connected
to a Switch (SPAN>Port Mirroring)
Métodos de identificación de WAF
Los métodos mas conocidos que podemos encontrar, se
encuetrarn:
·
Drop Action
→ Envia un paquete FIN / RST
·
Reglas Pre-Built → Cada WAF tiene sus propias Negative Secutity Signatures
·
Ataques
Side-Channel → Basados en Timing
behavior
Herramientas de Detección de WAF
Hay muchas herramientas y scripts que pueden detectar la
presencia y la huella digital del WAF :
·
imperva
detect.py
Realiza un un primer
test de base y luego realiza otros 5 test adicionales , sus resultados son muy
rápidos.

·
Paradox
WAF detection
·
F5
Cookie Decoder Burp extension
·
FatCat
SQL Injector
NMAP scripts
Los scripts de nmap pueden detectar varios productos
IDS, IPS, y WAF. Como los siguientes , BarracudaWAF,
PHPIDS, dotDefender, Imperva , Web Firewall, Blue
Coat SG 400.
Detectando WAF
usando NMAP
nmap
-p80 --script http-waf-detect

Fingerprinting de WAF usando NMAP
nmap
-p80 --script http-waf-fingerprint
Wafw00f.py
Wafw00f puede
identificar los patrones mas comunes de mas de 25 tipos de WAF
Fingerprinting de WAF usando WAFw00f
wafw00f.py

Un problema que nos podemos encontrar a la
hora de la detección es que los WAF oculten su identidad a
partir de los valores de las cookies y así como las respuestas HTTP de tipo 200 ,
así que será necesario realizar
test adicionales , por ejemplo
con imperva-detect.py.
Un tema importante a tratar , son las reglas que se
implementan , ya que tienen un impacto
en el funcionamiento de la aplicación web que esta detrás del WAF.
Una mala
configuración puede darnos problemas
tales como:
• Bloquear peticiones legitimas (falsos positivos)
• El conjunto de reglas necesita
ser revisado.
Y un conjunto de
reglas muy laxa sin excepciones puede :
·
Pueda
darnos (falsos negativos)
·
El
atacante eluda el WAF y por lo tanto
haga un exploit de la aplicación.
Continuara ….
Happy Hacking.
miércoles, 26 de octubre de 2016
Piratas del corsair

Autor: @toespar
Telegram
continúa buscando diferenciarse con funcionalidades que atraigan a los
usuarios. Viendo que el mundo de los videojuegos cada vez reúne a más gente en
teléfonos, qué mejor que poder hablar y jugar con tus amigos sin salir de la
conversación. Por ello, la propia plataforma ha creado varios juegos accesibles
desde el propio chat con tan solo poner @gamebot.

Viernes
por la tarde, y de repente, me llega una notificación de Telegram en un chat en
el que se mostraba el siguiente mensaje:
Se había abierto la veda. Y aunque he de reconocer que
no soy muy de jugar, el hecho de tener más puntuación que el resto me impulsaba
a ello. Tras unos breves intentos lo consigo.
Evidentemente, esto siguió varias veces más hasta que llegó
un punto en el que me resultaba imposible conseguir más puntos que el primero,
pero el asunto no podía quedar así. Por ello, me pongo a investigar cómo
funciona la puntuación del juego abriendo la versión desktop en el ordenador
que, casualmente, todavía no integra el juego en el propio chat sino que lo
abre directamente en el navegador.
Lo primero que hacemos es configurar BurpSuite y Firefox para obtener las distintas
peticiones que se realizan en función de los distintos escenarios del juego.
Ahora ya estamos listos para interceptar los paquetes
y observar cómo se realizan las peticiones, así que nos ponemos a jugar hasta
que nos eliminan. Tras un breve periodo de tiempo, vemos como van llegando
distintas peticiones a Burp, tanto del propio dominio que estamos analizando
como de otros. Por lo tanto, eliminamos las peticiones que no nos interesan,
quedándonos únicamente con aquellas que nos pueden ser de interés:

Tal y como vemos en la captura, la URL más interesante es
aquella relacionada con la asignación de puntuación: setScore. Adicionalmente, observamos también que la primera
petición se realiza para obtener el código JavaScript que ejecutará las
distintas funciones del juego, por lo que si buscamos la función que realiza el
setScore podremos entender cómo se
realiza la asignación de puntos:

Se realiza un post a la API setScore y se le pasan como parámetros data y score. Si seguimos
buscando de donde se obtienen los datos llegamos a la función main:

Dichos datos se obtienen de la URL del juego, la cual
contiene una cadena codificada en Base64 que contiene algunos parámetros como
el identificador del usuario, su nombre, el nombre del juego, el identificador
del chat, entre otros. Esta cadena varía en función del juego y puntuación
obtenida en la partida anterior.
Si ahora nos
centramos en el parámetro score,
podemos ver que este varía en función de las monedas obtenidas durante el
juego. No obstante, si nos fijamos en BurpSuite, observamos que el parámetro se
pasa sin ningún identificador que compruebe la autenticidad del valor obtenido
en el juego.

De esta forma, para obtener la puntuación que queramos únicamente
deberemos editar el parámetro score
en el cuerpo del mensaje. Para ello, mandamos la petición al repeater de BurpSuite
y editamos dicho valor:

Si todo ha ido bien, obtenemos la siguiente respuesta:

Y si nos fijamos en el chat…
Objetivo conseguido! Ahora sí somos los piratas del Corsair
;)
sábado, 22 de octubre de 2016
Fundamentals: Instalación de Proxychain y Tor en Kali

Autor: @txambe
En el articulo de hoy vamos a ver cómo instalar, configurar y utilizar
Proxychains y Tor en Kali Linux de manera a que nuestra privacidad esté siempre
garantizada y podamos que, aunque el servidor nos identifique, poder cambiar
nuestra identidad fácilmente pudiendo seguir manteniendo al máximo nuestro
anonimato.
Lo primero que debemos hacer es actualizar el sistema
con los parches y con las aplicaciones más recientes, para ello abriremos un
terminal y teclearemos:
- sudo apt-get update && sudo apt-get
upgrade
Esperaremos a que se actualicen los repositorios y se
instalen todas las actualizaciones antes de continuar con este proceso. Una vez
actualizado nuestro sistema instalaremos Tor en él desde los mismos
repositorios tecleando:
- sudo apt-get install tor

Cuando finalice la instalación de este módulo
iniciamos el servicio :
- sudo
service tor start
Comprobamos que se ha iniciado correctamente con:
- sudo
service tor status

Con Tor ya iniciado vamos a modificar el archivo de
configuración de Proxychains, para ello teclearemos:
- sudo nano /etc/proxychains.conf
En este archivo debemos realizar los siguientes
cambios:
- Des-comentar
borrando el # la línea dynamic_chain
- Comentar
con un # la línea strict_chain
- Añadir al
final de archivo: socks5
127.0.0.1 9050

Con estos pasos ya tenemos todo listo. Ya podemos
abrir una nueva pestaña de navegación anónima tecleando:
- proxychains iceweasel www.loquesea.net
Y comprobar desde cual-es-mi-ip.net que la IP que
obtenemos no es la misma que tenemos realmente en nuestra conexión, sino que
está ofuscada por la red Tor.
A partir de ahora, todo el tráfico que generemos en
la ventana del navegador abierta desde el comando anterior mucho cuidado
con esto ,será totalmente anónima, pudiendo establecer una conexión directa
no anónima desde cualquier otra ventana que abramos manualmente del mismo
navegador.
Happy h@cking
sábado, 15 de octubre de 2016
Creando URLs con CSRF implícito
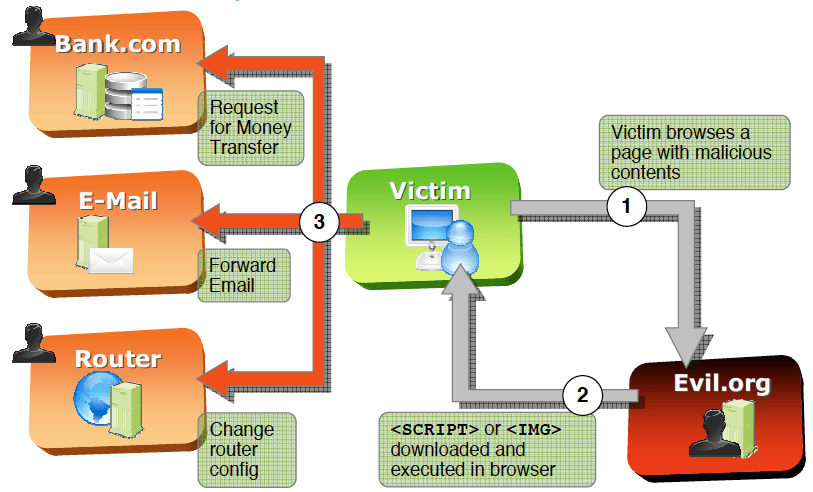
Autor: Samuel Lopez Saura
CSRF son las siglas de Cross Site Request Forgery. Esto es
una técnica a través de la cual un usuario víctima realiza determinadas
acciones programadas sin ser consciente de ello.
Imaginémonos el siguiente escenario.
El usuario A es administrador del sitio web
empresadeejemplo.com
Dentro de empresadeejemplo.com puede realizar las siguientes
acciones.
•
Ver empleados de la
empresa
•
Ver nómina de un empleado
•
Subir sueldo a un
empleado
•
Ver mi sueldo
•
Mi historial
El sitio web empresadeejemplo.com tiene un mecanismo de
sesiones y solo permite que el usuario admin realice las acciones marcadas en
rojo.
Para subir el sueldo de un empleado se encuentra con el
siguiente escenario.

El usuario administrador elige un usuario, la cantidad a
subir su sueldo y al darle a enviar genera una URL tal que
Dentro de la petición HTTP se manda la Cookie de sesión del
administrador. La aplicación comprobará que la cookie de sesión es válida y que
pertenece a un usuario con privilegios administrativos.
Dentro del código de la aplicación habrá algo parecido a
esto:
$usuario = $_REQUEST[‘usuario’];
$aumento = $_REQUEST[‘aumento’];
→ si el usuario al que corresponde la sesión es admin
subir_sueldo($usuario,
$cantidad);
header(‘Location:
/admin’); /* Redirigimos al panel de administración */
→ si el usuario
al que corresponde la sesión no es admin
header(‘Location:
/’); /* Redirigimos a la raíz del sitio
*/
La aplicación funcionaría y en principio un usuario que no
fuera admin no podría realizar la acción.
La pregunta es, ¿qué pasaría si admin hiciera clic en http://empresadeejemplo.com/admin/subirsueldo.php?usuario=juan_ejemplo_perez&aumento=9000
sin ser consciente de ello?
Su navegador realizaría una petición GET y mandaría su cookie de sesión el servidor
comprobaría que realmente es admin quién está realizando la acción y subiría en
9000€ el sueldo al empleado juan ejemplo perez.
Pero ¿cómo va a hacer clic en eso el administrador? Volvamos
atrás, cuando hacemos clic emitimos una petición GET al servidor y esta la
procesa. Esta petición también la realizamos cuando, por ejemplo, cargamos una
imagen. Entonces si el usuario administrador visitara un sitio web que cargase
esa URL su navegador emitiría una petición GET al servidor como si el propio
administrador conscientemente hiciera la petición.
< img src=” http://empresadeejemplo.com/admin/subirsueldo.php?usuario=juan_ejemplo_perez&aumento=9000”/>
– Una imagen dice más de
mil palabras
Además, ¿y si los datos se pasaran
por el método POST en lugar de por el método GET?
Desde PHP podemos recibir
parámetros con $_GET, $_POST, $_REQUEST. El primero contiene un array
asociativo con los datos mandados por el método GET. El segundo por el método
POST y el tercero por cualquiera de los dos métodos.
La utilización de $_REQUEST es una
práctica muy común y sin una validación adecuada podemos enviar en un método
GET parámetros que el servidor procesaría como si fuera un método POST para un
campo que se espera ser recibido solo por POST. Es decir, en una URL podríamos
simular un “POST” implícito en ella si al recibir el parámetro lo recibiéramos
mediante $_REQUEST.
junto a un método POST los
parámetros de usuario y aumento.
Sería igual a la url → http://empresadeejemplo.com/admin/subirsueldo.php?usuario=juan_ejemplo_perez&aumento=9000
Si el documento PHP tuviese en
cuenta por donde vienen los datos. Utilizando $_POST o $_GET en lugar de la
opción genérica $_REQUEST. Y la acción fuera dada por el método POST habría que
simular el envío de un formulario con esos valores al servidor pero el
mecanismo sería muy similar a la opción de la imagen con la excepción de que
sería un código javascript quién realizase la petición POST o activase el envío
de un formulario.
La tarde del miércoles creé una
micro aplicación que bajo un fin educativo automatizaba este proceso.

Arriba a la derecha tenemos un
botón que pone Nueva URL. Esto levantará una ventana donde podremos poner los
parámetros.


Lo que nos genera una URL como la
siguiente:
http://cj.curiosoinformatico.com/?r=http://honeycon.eu&YfwEijRLSOJqYRvvzucaTDD6abLA0rZrPKaTpxSEmWAjoJpGjYVPvSEq8XHZzLsSYlIA9reFyahfWUjVolTN3q2JtU5C6y7Q6jZT&c=http://empresadeejemplo.com/admin/subirsueldo.php?usuario=juan_ejemplo_perez&aumento=9000
Cuando copiemos la URL y la
peguemos en la barra del navegador nos encontraremos con esto:

Lo que está pasando en realidad es
lo siguiente:
• Se
accede a http://cj.curiosoinformatico.com, lo primero en cargar es un script que comprueba si
tenemos parámetros en la URL que nos indiquen a donde redirigir y donde hacer
clic.
• De tenerlos carga el sitio que hemos escogido para hacer
clic como una imagen nada sospechosa y cambia la URL del documento al sitio
destino.
• No obstante como la URL es un poco sospechosa podemos usar
un acortador de enlaces como bit.ly para hacerla más confiable.
¡Magia!
Esta poderosa URL subirá nuestro sueldo en 9000 euros sin que nadie se entere y
le informará a nuestro jefe de un evento donde aprender y mejorar su seguridad.
http://bit.ly/2ea3VFM
Nota del autor: Actualmente
la página no tiene soporte para peticiones POST -si tiene para GET y para los POST
que recoja PHP a través de $_REQUEST (que en realidad se envían como GET)-.
Imagino que en un hueco libre que tenga se lo pondré pero si alguien quiere
adelantarse aquí dejo el github del mismo.
https://github.com/curiosoinformatico/two_steps_redirector
Tras publicar este articulo Vicente Aguilera Diaz se puso en contacto con nosotros y nos indico varios interesantes enlaces de sus publicaciones sobre CSRF y redes sociales, aquí podéis consultarlos:
Caso Facebook: http://www.isecauditors.com/advisories-2011#2011-002
Caso Linkedin: http://seclists.org/fulldisclosure/2013/Mar/216
Caso Gmail: http://www.securiteam.com/securitynews/5ZP010UQKK.html
Muchas gracias Vicente.
******************* ACTUALIZACIÓN *********************
Tras publicar este articulo Vicente Aguilera Diaz se puso en contacto con nosotros y nos indico varios interesantes enlaces de sus publicaciones sobre CSRF y redes sociales, aquí podéis consultarlos:
Caso Facebook: http://www.isecauditors.com/advisories-2011#2011-002
Caso Linkedin: http://seclists.org/fulldisclosure/2013/Mar/216
Caso Gmail: http://www.securiteam.com/securitynews/5ZP010UQKK.html
Muchas gracias Vicente.
Suscribirse a:
Entradas (Atom)